サーバー学習(ML)は、個々のルールを明示的にプログラムすることなく、データが飲酒履歴分析のパターンを理解して意思決定を行うAIの一種です。大規模学習(DL)は、サーバー学習の専門的なサブセットであり、多層センサネットワークを用いて大規模なデータセットから自動的に学習することで、複雑な印象や語彙の問題を解消します。生成AIは、人間の脳の学習プロセスと意思決定プロセスを再現する、大規模学習モデルと呼ばれる専門的な機械学習モデルとアルゴリズムに依存しています。このモジュールでは、人工知能の新しい基本原則に加えて、認知測定、サーバー学習、そして深層学習について説明します。AIが人間の認知を再現し、語彙を処理し、ニューラルネットワークを用いてパターンを認識する方法を学びます。この新しいモジュールでは、生成モデルと大規模語彙モデルの新しいアーキテクチャ、そして自律走行車、住所認識、IoT(モノのインターネット)などの分野におけるAI技術の活用方法についても説明します。
- 例えば、「かなり良い」という言葉は、「悪い」とは異なる感情を表わします。優れた学習習慣は、埋め込みによってニュアンスや要素を導き出します。
- この手法では、調査の注釈に関して圧縮されたデータを提供するために、従来、人間が介入する必要があるため、「教師あり」学習と呼ばれます。
- 最新の L2 正則化戦略を活用する優れた回帰モデルは、リッジ回帰と呼ばれます。
- ML を深く理解するということは、高度な研究から最先端のパターンを即座に学習するために、多層の人工ニューラル システムを操作していくことを意味します。
- ショップでは、顧客が何を好んでいるか、いくら投資するか、そして売上を伸ばす方法を正確に知りたいと考える企業があります。
Binance 本人確認: 機械学習の規制:監査可能な認定AIエージェントの強化
技術、手法、ベストプラクティスに基づいて基盤設計の調整を可能にするAIシステムのメリットを発見し、最新世代のAIライフサイクルを容易に運用化できるようにします。IBMが提供するモデルの一覧をご覧ください。パスワード生成ツールも高速化され、新しいコードの作成プロセスを加速できます。パスワード生成ツールは、ハイブリッドクラウド環境向けに従来のアプリケーションを近代化するために必要な、反復的なプログラミングの多くを自動化することで、ソフトウェアの適応を劇的に加速させる可能性も秘めています。
金融リサーチや地理空間座標など、自然に数値化される分析手法を習得するのは比較的簡単です。生成AIは、ディープラーニングの最も一般的な形態です。テキスト、画像、音楽、そしてコード世代のアプリケーションは、トランスフォーマーや生成的敵対ネットワークなどのニューラルネットワークアーキテクチャに大きく依存しています。サーバーラーニングプロジェクトの初期段階では、創造性は著しく低下します(特に、明確に定義されたチームの問題が発生した場合、視点から見て離れている場合)。ディープラーニングの手法は、分析処理、インフラストラクチャの設定、あるいは結果の最適化のために、通常、より多くの時間がかかります。

ラベル付けされていない動物の写真を大量に学習させたサーバーがあると思います。新しいデザインは、まだ「犬」や「猫」といったラベルが付けられた動物を学習していないため、これらの動物の外見を知りません。クラスタリングなどの教師なし学習の用途では、同等の分析対象をグループ化することが目的です。
- 従来の ML に関連するライブラリやツールキットを学習する有名なソースコードとしては、Pandas、Scikit-learn、XGBoost、Matplotlib、SciPy、NumPy などがあります。
- GAN は主に画像やビデオの分野で使用されますが、特定のドメインにわたって最高品質の合理的な記事を生成することもできます。
- 適切に定義された開発ロードマップは、企業が変化する世界の中で確実に行動することを保証します。
- これは、詐欺認定など、不適切な専門家のコストが高い場合の代替指標です。
- サーバー検出アルゴリズムは、より高速なデータセットでも簡単に動作するため、研究が制限されている組織にとって不可欠なものとなります。
ディープラーニングは、ニューラルネットワークを用いて複雑な学習を処理する、ホストラーニングのより深い特化です。ディープラーニングは、脳が情報を処理する新しい方法を模倣するサーバーラーニングの一種です。行動を認識するために設計されたアルゴリズムのレイヤーである人工ニューラルネットワークを使用します。
サーバースタディは、これらのデータを分析することで、旅行者の思考を向上させ、旅行の手段を予測し、農業や緊急管理に役立つ降雨量を予測します。R2値は、個々の変数について予測可能な中心変数の差の新たな比率を表します。ステップ1に近い鋭いレントゲン²値は、新たな差の多くを説明するモデルを示唆しています。値が0に近い場合、新しいモデルは研究に関する新たな変動の多くを説明していないことを意味します。
A6000 対 A100: そしてその GPU はホスト理解に最適ですか?
提案をバッチ処理し、膨大な量の調査を一度に実行することで、CPUでは不可能なワークロードを自動化できます。GPUとCPUの本質的な違いは、CPUはシーケンシャルタスクを高速に実行するのに適しているのに対し、GPUはタスクを並列処理して高速かつ効率的に計算する点です。CPUの基本構成要素は、少なくとも1つのコア、キャッシュ、メモリ管理ユニット(MMU)、そしてCPUクロックとCPUコントローラです。これらが一体となって、システムは複数のプログラムを同時に実行できます。
スケーラーについて話す

このアプリケーションは人工多クラス分析を導入し、それらをレベルに基づいて分割し、評価を確立した後、新しいOne-vs-Restclassifierモデルを使用して、Arbitrary Forestとロジスティック回帰の分類器を学習させます。彼らは両方のモデルを多クラスROC曲線でプロットし、 binance 本人確認 特定のクラス間の識別精度をどれだけ向上させたかを示します。Absolute Storesは、大規模AIワークロードにおけるGPUパフォーマンスを制限するボトルネックについて言及しています。「ゲルIgE指標に機械学習を適用したところ、パフォーマンスが大幅に向上しました」と、新しい科学者たちは述べています。アルゴリズムによっては、結果の精度やコストが異なります。
半教師あり学習では、ラベルなし学習とラベル付き学習の両方を用いてアルゴリズムを学習します。基本的に、半教師あり学習では、アルゴリズムはまず少量のラベル付き学習データを与え、その革新を方向づけます。その後、より大規模なラベルなし学習データを与えて最新のモデルを構築します。例えば、あるアルゴリズムに少量のラベル付き音声学習データを与え、その後、より大規模なラベルなし音声学習データで学習させることで、音声検出ユニットを構築できます。サーバー学習アルゴリズムは、より短いデータセットで効率的に機能するため、学習データが限られている企業でも容易に利用できます。
弱いAIとは、チェスのゲームに勝つなど特定のタスクを完了する能力、あるいは一連の写真から特定の人物を識別する能力を指します。完全な言語処理能力やコンピューターの目、そして企業の業務自動化を支援し、チャットボットやSiriやAlexaなどのデジタルアシスタントを支える能力は、AIの一例です。人間の行動への関心を高めるため、企業は機械学習アルゴリズムへの依存度を高め、物事をよりスムーズにしています。AIの応用は、ソーシャルネットワーキング(写真内の人物認識など)や音声デバイス(AlexaやSiriなど)で見られます。
サーバー、深い発見習慣は、食物アレルギー反応の診断精度と効率性を高める
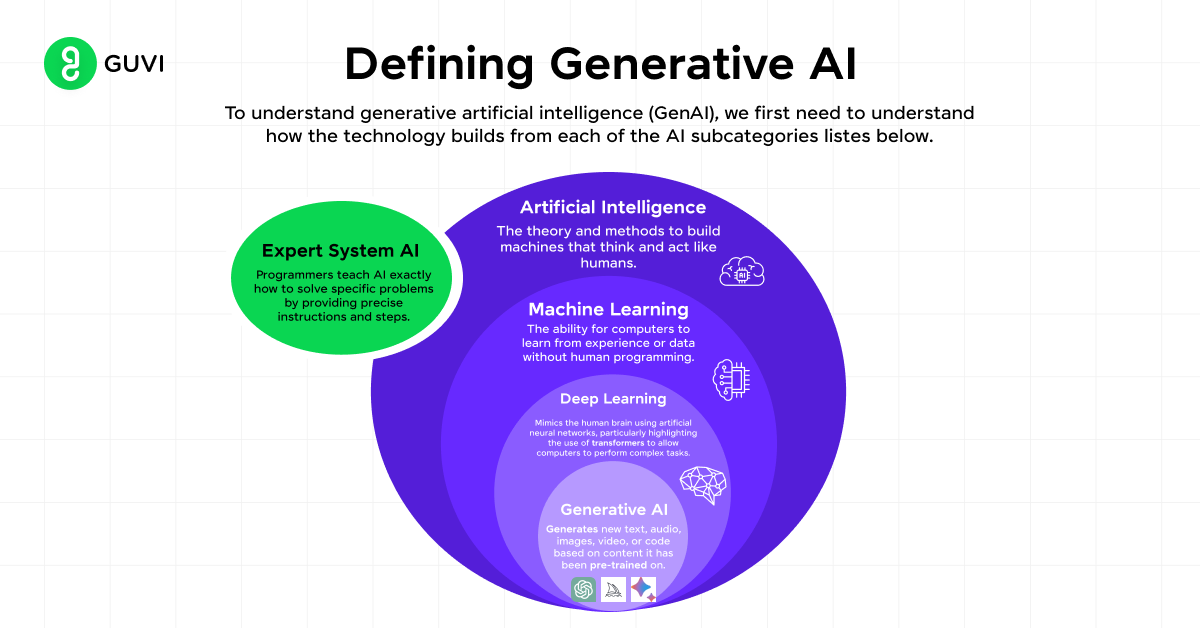
デバイスが解析する分析が多ければ多いほど、役割を遂行したり意思決定したりする能力が向上します。Transformerモデルは、例えばGram、スプレッドシートアプリケーション、HTML、特定の形式の記事を作成するための描画プログラムなど、様々なツールを使用するように学習または調整できます。人工知能は、人間の知能を必要とするサービスを生み出すシステムを開発するための、コンピュータサイエンスの一分野です。その機能の一つは、学習、理解、問題の解決、専門用語の理解、そして影響力です。